Provides functions related to the Lasso distribution, including the normalizing constant,
probability density function, cumulative distribution function, quantile function, and
random number generation for given parameters a, b, and c.
Additional utilities include the Mills ratio, expected value, and variance of the distribution.
The package also implements modified versions of the Hans and Park–Casella Gibbs sampling algorithms
for Bayesian Lasso regression.
Usage
zlasso(a, b, c, logarithm)
dlasso(x, a, b, c, logarithm)
plasso(q, a, b, c)
qlasso(p, a, b, c)
rlasso(n, a, b, c)
elasso(a, b, c)
vlasso(a, b, c)
mlasso(a, b, c)
MillsRatio(d)
Modified_Hans_Gibbs(X, y, beta_init, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init, thin, verbose,
tune_lambda2, rao_blackwellization)
Modified_PC_Gibbs(X, y, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init, thin, verbose)Arguments
- x, q
Vector of quantiles (vectorized).
- p
Vector of probabilities.
- a
Vector of precision parameter which must be non-negative.
- b
Vector of off set parameter.
- c
Vector of tuning parameter which must be non-negative values.
- n
Number of observations.
- logarithm
Logical. If
TRUE, probabilities are returned on the log scale.- d
A scalar numeric value. Represents the point at which the Mills ratio is evaluated.
- X
Design matrix (numeric matrix).
- y
Response vector (numeric vector).
- a1
Shape parameter of the prior on \(\lambda^2\).
- b1
Rate parameter of the prior on \(\lambda^2\).
- u1
Shape parameter of the prior on \(\sigma^2\).
- v1
Rate parameter of the prior on \(\sigma^2\).
- nsamples
Number of Gibbs samples to draw.
- beta_init
Initial value for the model parameter \(\beta\).
- lambda_init
Initial value for the shrinkage parameter \(\lambda^2\).
- sigma2_init
Initial value for the error variance \(\sigma^2\).
- thin
Thinning interval for the MCMC chain. Only every `thin`-th draw is stored. Default is 1 (no thinning).
- verbose
Integer. If greater than 0, progress is printed every
verboseiterations during sampling. Set to 0 to suppress output.- tune_lambda2
Logical; if TRUE (default), the tuning parameter \(\lambda^2\) is estimated during sampling.
- rao_blackwellization
Logical; if TRUE, Rao–Blackwellization is applied to improve posterior estimation. Default is FALSE.
Value
zlasso,dlasso,plasso,qlasso,rlasso,elasso,vlasso,mlasso,MillsRatio: return the corresponding scalar or vector values related to the Lasso distribution and a numeric value representing the Mills ratio.Modified_Hans_Gibbs: returns a list containing:mBetaMatrix of MCMC samples for the regression coefficients \(\beta\), with
nsamplesrows andpcolumns.vsigma2Vector of MCMC samples for the error variance \(\sigma^2\).
vlambda2Vector of MCMC samples for the shrinkage parameter \(\lambda^2\).
mAMatrix of sampled values for parameter \(a_j\) of the Lasso distribution for each \(\beta_j\).
mBMatrix of sampled values for parameter \(b_j\) of the Lasso distribution for each \(\beta_j\).
mCMatrix of sampled values for parameter \(c_j\) of the Lasso distribution for each \(\beta_j\).
Modified_PC_Gibbs: returns a list containing:mBetaMatrix of MCMC samples for the regression coefficients \(\beta\).
vsigma2Vector of MCMC samples for the error variance \(\sigma^2\).
vlambda2Vector of MCMC samples for the shrinkage parameter \(\lambda^2\).
mMMatrix of estimated means of the full conditional distributions of each \(\beta_j\).
mVMatrix of estimated variances of the full conditional distributions of each \(\beta_j\).
va_tilVector of estimated shape parameters for the full conditional inverse-gamma distribution of \(\sigma^2\).
vb_tilVector of estimated rate parameters for the full conditional inverse-gamma distribution of \(\sigma^2\).
vu_tilVector of estimated shape parameters for the full conditional inverse-gamma distribution of \(\lambda^2\).
vv_tilVector of estimated rate parameters for the full conditional inverse-gamma distribution of \(\lambda^2\).
Details
If \(X \sim \text{Lasso}(a, b, c)\) then its density function is: $$ p(x;a,b,c) = Z^{-1} \exp\left(-\frac{1}{2} a x^2 + bx - c|x| \right) $$ where \(x \in \mathbb{R}\), \(a > 0\), \(b \in \mathbb{R}\), \(c > 0\), and \(Z\) is the normalizing constant.
More details are included for the CDF, quantile function, and normalizing constant in the original documentation.
See also
normalize for preprocessing input data before applying the samplers.
Examples
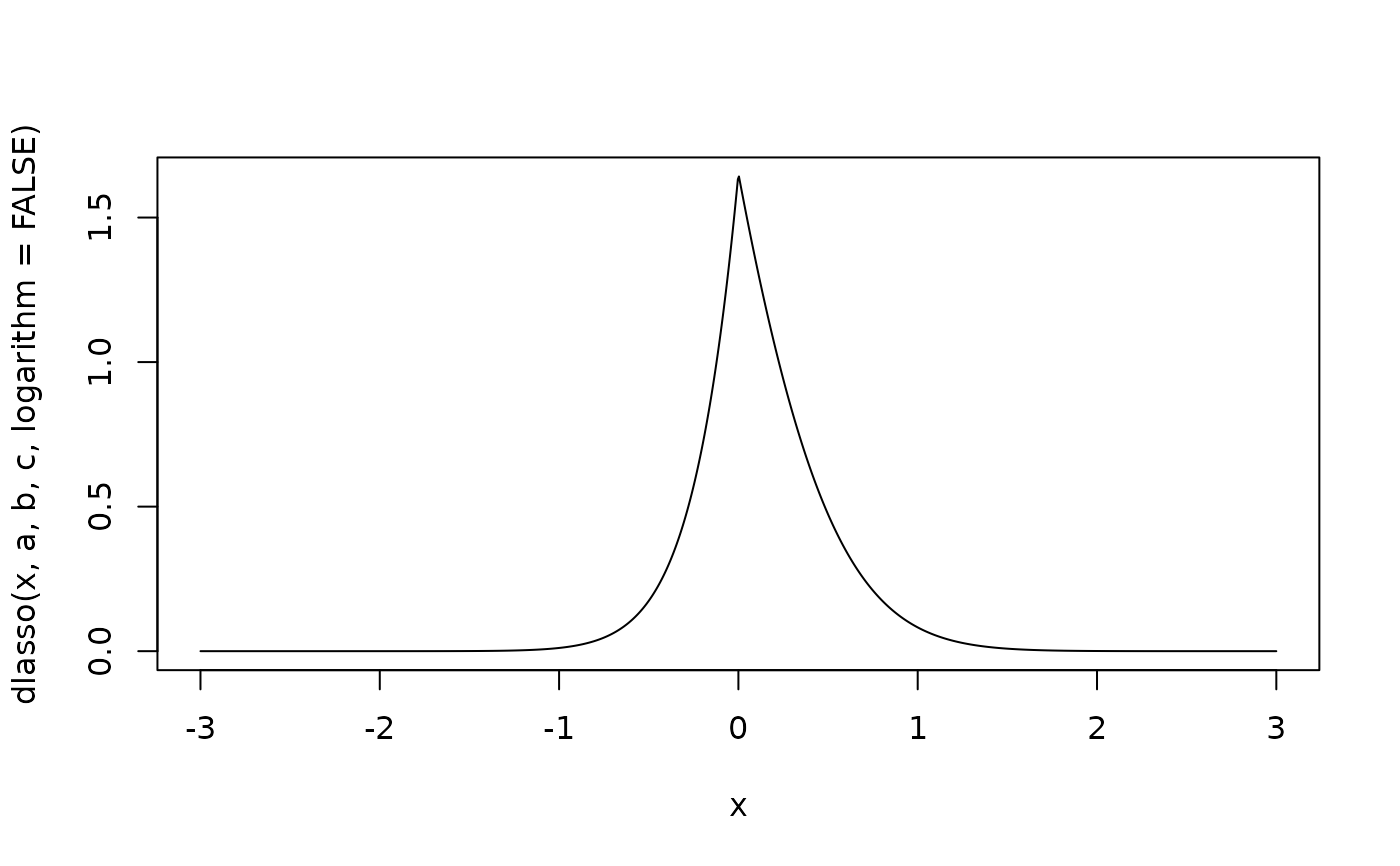
a <- 2; b <- 1; c <- 3
x <- seq(-3, 3, length.out = 1000)
plot(x, dlasso(x, a, b, c, logarithm = FALSE), type = 'l')
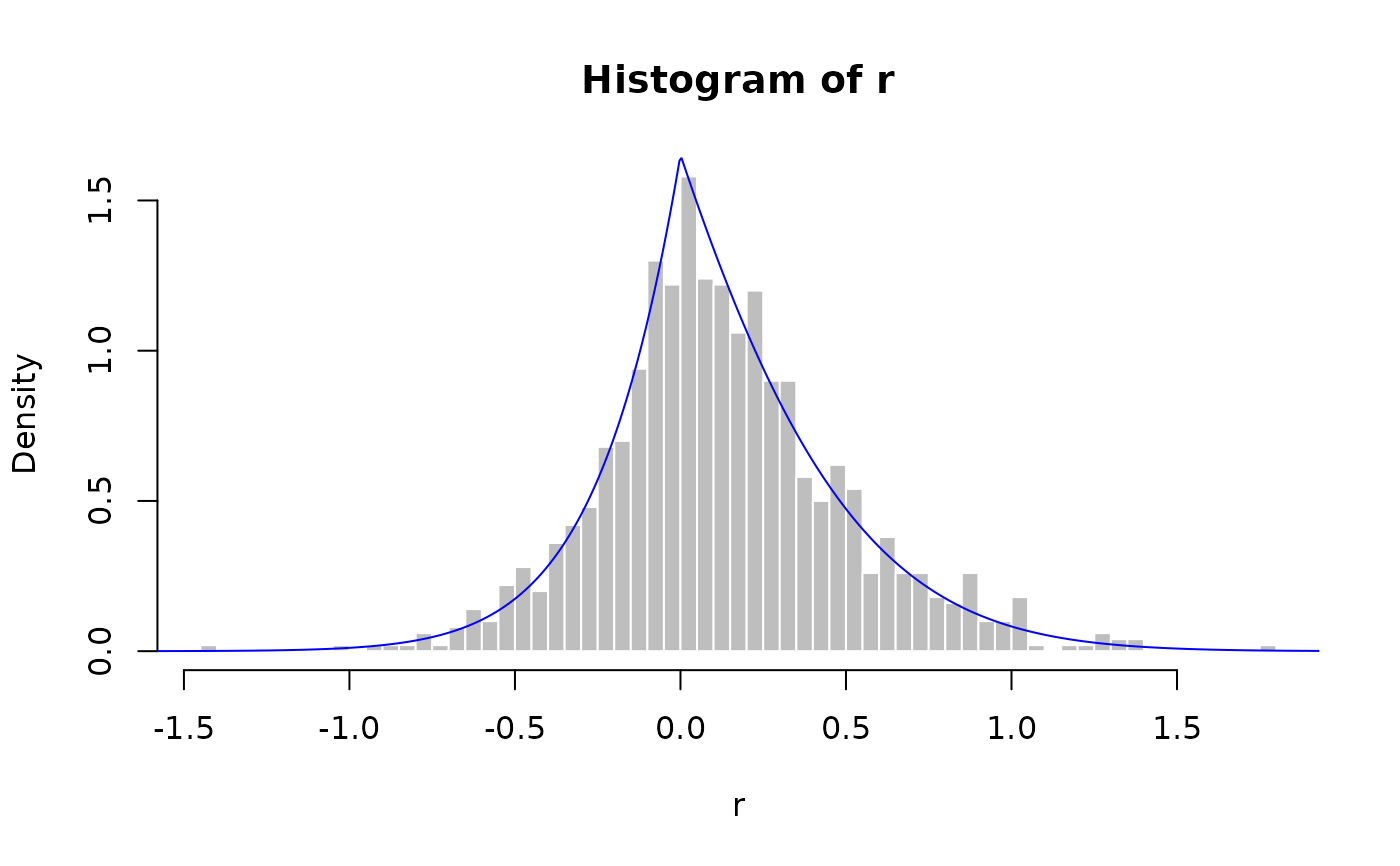
 r <- rlasso(1000, a, b, c)
hist(r, breaks = 50, probability = TRUE, col = "grey", border = "white")
lines(x, dlasso(x, a, b, c, logarithm = FALSE), col = "blue")
r <- rlasso(1000, a, b, c)
hist(r, breaks = 50, probability = TRUE, col = "grey", border = "white")
lines(x, dlasso(x, a, b, c, logarithm = FALSE), col = "blue")
 plasso(0, a, b, c)
#> [1] 0.3739435
qlasso(0.25, a, b, c)
#> [1] -0.08945799
elasso(a, b, c)
#> [1] 0.1218306
vlasso(a, b, c)
#> [1] 0.1287739
mlasso(a, b, c)
#> [1] 0
MillsRatio(2)
#> [1] 0.4213692
# The Modified_Hans_Gibbs() function uses the Lasso distribution to draw
# samples from the full conditional distribution of the regression coefficients.
y <- 1:20
X <- matrix(c(1:20,12:31,7:26),20,3,byrow = TRUE)
a1 <- b1 <- u1 <- v1 <- 0.01
sigma2_init <- 1
lambda_init <- 0.1
beta_init <- rep(1, ncol(X))
nsamples <- 1000
verbose <- 100
tune_lambda2 <- TRUE
rao_blackwellization <- FALSE
Output_Hans <- Modified_Hans_Gibbs(
X, y, beta_init, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init,
verbose, tune_lambda2, rao_blackwellization
)
#> iter: 0 lambda2: 0.01 sigma2: 87.1593
#> iter: 1 lambda2: 0.01 sigma2: 95.9609
#> iter: 2 lambda2: 0.01 sigma2: 50.9426
#> iter: 3 lambda2: 0.01 sigma2: 52.1754
#> iter: 4 lambda2: 0.01 sigma2: 80.7908
#> iter: 5 lambda2: 0.01 sigma2: 74.9386
#> iter: 6 lambda2: 0.01 sigma2: 69.402
#> iter: 7 lambda2: 0.01 sigma2: 50.4434
#> iter: 8 lambda2: 0.01 sigma2: 41.5339
#> iter: 9 lambda2: 0.01 sigma2: 39.48
colMeans(Output_Hans$mBeta)
#> [1] -0.12758493 0.08436887 0.10115044
mean(Output_Hans$vlambda2)
#> [1] 0.001
Output_PC <- Modified_PC_Gibbs(
X, y, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init, verbose)
#> iter: 0
colMeans(Output_PC$mBeta)
#> [1] 0.03753301 -0.02313929 0.04647570
mean(Output_PC$vlambda2)
#> [1] 1.66784
plasso(0, a, b, c)
#> [1] 0.3739435
qlasso(0.25, a, b, c)
#> [1] -0.08945799
elasso(a, b, c)
#> [1] 0.1218306
vlasso(a, b, c)
#> [1] 0.1287739
mlasso(a, b, c)
#> [1] 0
MillsRatio(2)
#> [1] 0.4213692
# The Modified_Hans_Gibbs() function uses the Lasso distribution to draw
# samples from the full conditional distribution of the regression coefficients.
y <- 1:20
X <- matrix(c(1:20,12:31,7:26),20,3,byrow = TRUE)
a1 <- b1 <- u1 <- v1 <- 0.01
sigma2_init <- 1
lambda_init <- 0.1
beta_init <- rep(1, ncol(X))
nsamples <- 1000
verbose <- 100
tune_lambda2 <- TRUE
rao_blackwellization <- FALSE
Output_Hans <- Modified_Hans_Gibbs(
X, y, beta_init, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init,
verbose, tune_lambda2, rao_blackwellization
)
#> iter: 0 lambda2: 0.01 sigma2: 87.1593
#> iter: 1 lambda2: 0.01 sigma2: 95.9609
#> iter: 2 lambda2: 0.01 sigma2: 50.9426
#> iter: 3 lambda2: 0.01 sigma2: 52.1754
#> iter: 4 lambda2: 0.01 sigma2: 80.7908
#> iter: 5 lambda2: 0.01 sigma2: 74.9386
#> iter: 6 lambda2: 0.01 sigma2: 69.402
#> iter: 7 lambda2: 0.01 sigma2: 50.4434
#> iter: 8 lambda2: 0.01 sigma2: 41.5339
#> iter: 9 lambda2: 0.01 sigma2: 39.48
colMeans(Output_Hans$mBeta)
#> [1] -0.12758493 0.08436887 0.10115044
mean(Output_Hans$vlambda2)
#> [1] 0.001
Output_PC <- Modified_PC_Gibbs(
X, y, a1, b1, u1, v1,
nsamples, lambda_init, sigma2_init, verbose)
#> iter: 0
colMeans(Output_PC$mBeta)
#> [1] 0.03753301 -0.02313929 0.04647570
mean(Output_PC$vlambda2)
#> [1] 1.66784